赛题链接:https://www.kaggle.com/competitions/ml-olympiad-detect-hallucinations-in-llms
任务分析:这是一个文本分类任务,难点在于如何提取文本特征、建立文本关系特征,以及如何解决类别不平衡问题
运行环境、使用框架、语言
操作系统:Linux ubuntu 4.15.0-213-generic #224-Ubuntu SMP Mon Jun 19 13:30:12 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
硬件环境: Intel® Xeon® Gold 6226R CPU @ 2.90GHz + NVIDIA GeForce RTX 3090 * 8 (CUDA Version: 12.4)
语言和运行环境:python 3.9.21 (main, Dec 11 2024, 16:24:11) + jupyter notebook 7.2.2
使用框架:pytorch 2.5.1+cu124
lab2文件夹下,有6个文件:
data_process.ipynb:数据处理源代码StratifiedKFold.ipynb:交叉验证,选择合理超参数源代码idea_model.ipynb:训练模型,生成测试结果源代码submissions.csv:测试结果lab2_report.pdf:实验报告
由于训练集和测试集文件太大,以下文件没有放入
test.csv:测试集train.csv:训练集train_data.csv:处理后的训练集test_data.csv:处理后的测试集trained_model.pth:模型权重
数据分析、特征设计、抽取、处理
将训练集和测试集放到一块做特征处理,抛开Target和Id以外,特征有:Prompt和Answer。这两个特征都是长文本特征,所以说这个任务的关键就在于,如何处理文本。
简单文本特征抽取
新增3列基础特征,分别表示 Prompt长度,Answer长度 以及 Answer是否为空
代码如下:
def feature_engineering (df_in ): df = df_in.copy() df["Prompt_n" ] = df["Prompt" ].apply(lambda x : len (x.split())) df["Answer_n" ] = df["Answer" ].apply(lambda x : len (str (x).split())) df["isna" ] = 0 df.loc[df["Answer" ].isna(), "isna" ] = 1 df.loc[df["Answer" ].isna(), "Answer_n" ] = 0 df.loc[df["Answer" ].isna(), "Answer" ] = "NAN" df['Prompt_n' ] = (df['Prompt_n' ] - df['Prompt_n' ].mean()) / df['Prompt_n' ].std() df['Answer_n' ] = (df['Answer_n' ] - df['Answer_n' ].mean()) / df['Answer_n' ].std() return df
tokenizer
tokenizer将句子分割成词元序列,建立一个字典,给每个词一个整型id,这一既能保持时序特征,又方便计算机处理。
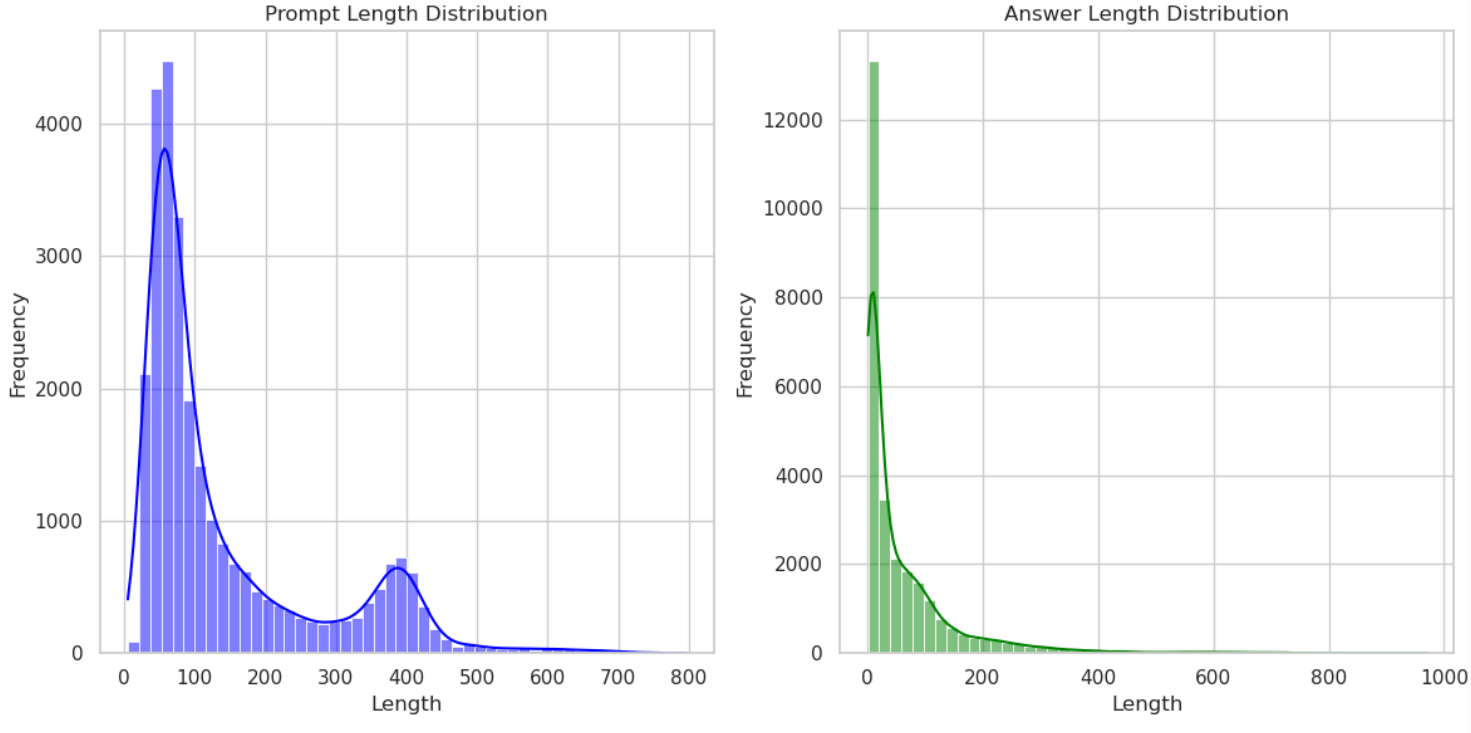
首先看一下,Prompt的句长和Answer的句长,可以发现长度大于512的Prompt和长度大于256的Answer都很少,所以在做tokenizer时,我们设置prompt的最大长度为512,Answer的最大长度为256。
代码如下:
from transformers import BertTokenizermax_len_prompt=512 max_len_answer=256 model_name = "huawei-noah/TinyBERT_General_4L_312D" tokenizer = BertTokenizer.from_pretrained(model_name) prompt_encodings = tokenizer(df_data['Prompt' ].tolist(), padding=True , truncation=True , return_tensors='pt' ,max_length=max_len_prompt) answer_encodings = tokenizer(df_data['Answer' ].tolist(), padding=True , truncation=True , return_tensors='pt' ,max_length=max_len_answer)
生成训练集和测试集
在源码文件data_process.ipynb中,将数据处理完之后,存储为train_data.csv和test_data.csv,分别为训练集和测试集
<class 'pandas.core.frame.DataFrame'> RangeIndex: 16687 entries, 0 to 16686 Columns: 1541 entries, Id to labels dtypes: float64(2), int32(1), int64(1538) memory usage: 196.1 MB <class 'pandas.core.frame.DataFrame'> RangeIndex: 11125 entries, 16687 to 27811 Columns: 1540 entries, Id to Answer_attention_mask_255 dtypes: float64(2), int64(1538) memory usage: 130.7 MB
训练集中最后一列为label,即Target,所以比测试集列数大1。
其余的列,训练集和测试集是一样的,具体表示为:Id,Prompt_n, Answer_n, is_na, 后面紧跟prompt对应的token和mask_attention,这两者的宽度都为max_len_prompt,后面再紧跟answer对应的token和mask_attention,这两者的宽度都为max_len_answer。
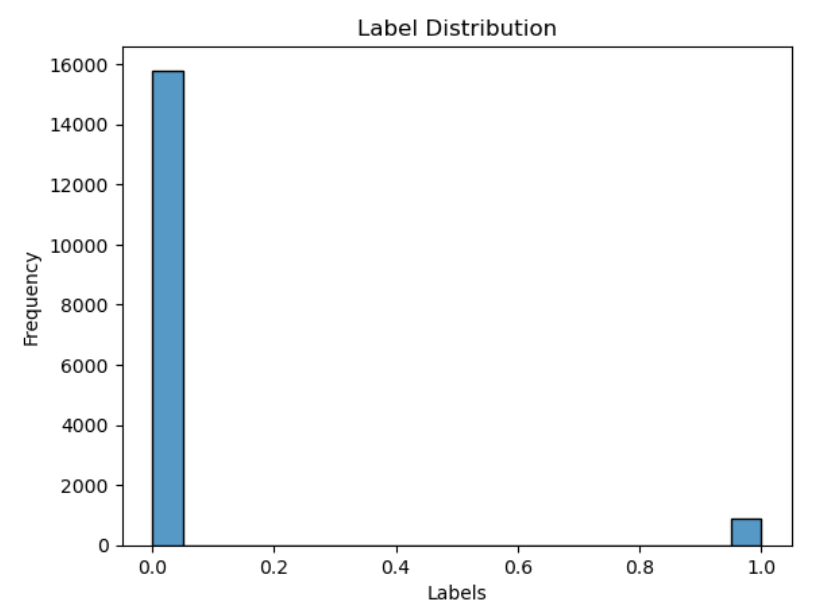
应对:类别不平衡 – focal_loss
可见标签1的占比远小于标签0。计算一下具体比值为5793 /894=17.6655480984。
我使用focal loss来解决这一类别不平衡问题:
Focal Loss 是一种专门为解决类别不平衡问题设计的损失函数,最早由 Facebook 的研究人员在论文《Focal Loss for Dense Object Detection》中提出。它常用于目标检测任务(例如 RetinaNet),以缓解正负样本比例失衡对模型训练的影响。
Focal Loss 的数学公式如下:
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) FL(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t)
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t )
p t p_t p t
$ p_t = \begin{cases} p, & \text{如果标签为正样本} \ 1-p, & \text{如果标签为负样本} \end{cases} $
其中 p 是正类别的预测概率。
α t \alpha_t α t
γ \gamma γ γ = 0 \gamma=0 γ = 0
( 1 − p t ) γ (1-p_t)^\gamma ( 1 − p t ) γ p t p_t p t p t p_t p t
代码如下:
class FocalLoss (nn.Module): def __init__ (self, alpha, gamma=2 , reduction='mean' ): """ alpha: tensor数组 (num_label,1) gamma: 难易样本调节因子。 reduction: 损失的聚合方式,支持 'mean', 'sum', or 'none'。 """ super (FocalLoss, self ).__init__() self .alpha = alpha self .gamma = gamma self .reduction = reduction def forward (self, pred, target ): ''' pred: tensor数组 (batch_size,num_labels) 每个种类的预测概率 (不一定softmax) target: tensor数组 (batch_size,) 真实标签 ''' device = target.device self .alpha = self .alpha.to(device) pred = F.softmax(pred, dim=1 ) pred=pred.gather(1 , target.unsqueeze(1 )) loss = -(1 - pred) ** self .gamma * torch.log(pred) selected_alpha = torch.matmul(F.one_hot(target, num_classes=2 ).float (), self .alpha) loss = loss * selected_alpha if self .reduction == 'mean' : return torch.mean(loss) elif self .reduction == 'sum' : return torch.sum (loss) else : return loss
模型设计
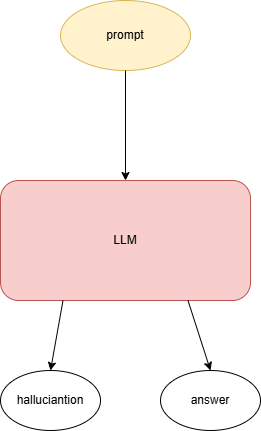
如下图所示,给定prompt,大语言模型(LLM)可以生成answer和hallucinations,所以我认为,hallucinations直接由Prompt和LLM决定,而answer和hallucination之间应该是互相验证的关系。
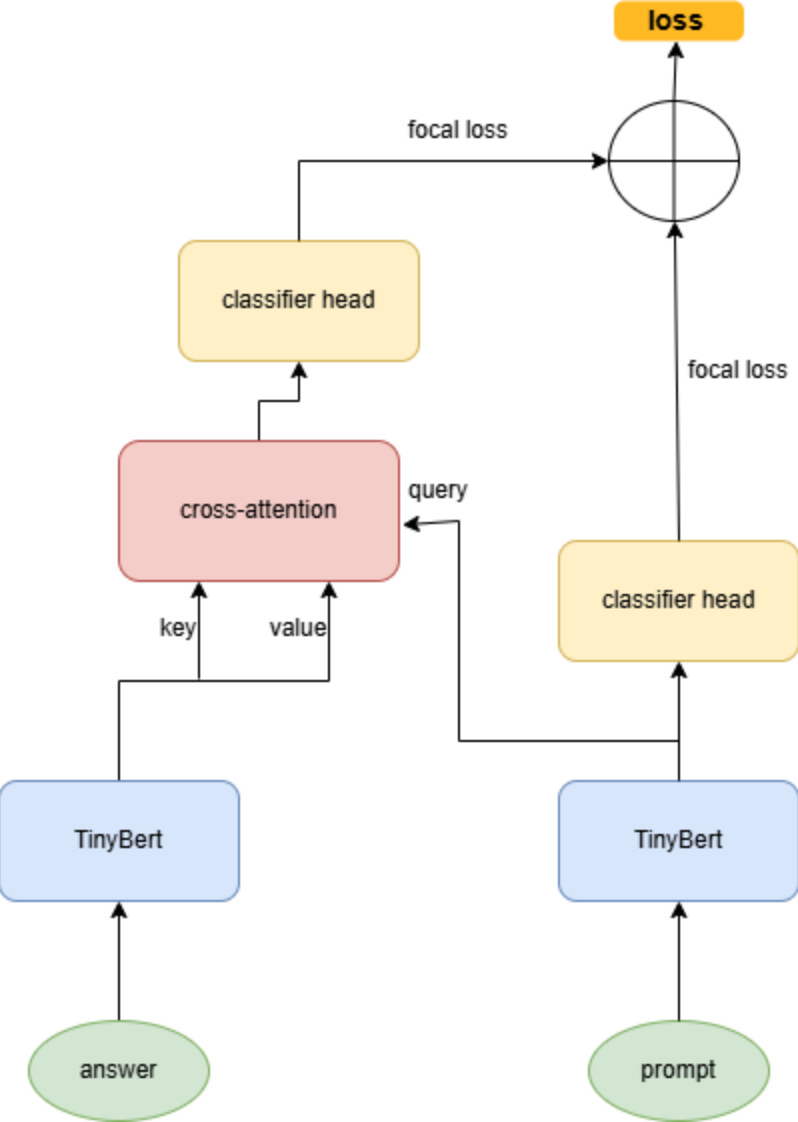
基于以上思想,我设计了如下模型结构:
loss函数由两个分类器的损失组成,一个是直接基于prompt生成的分类器,另一个是prompt结合answer后生成的分类器。这是因为,我觉得hallucination是直接由prompt决定的,所以直接训练一个基于prompt的分类器,为了加强这个分类器,将prompt混合answer信息,再训练一个分类器,即可。最终我们可以使用左上角的分类器做文本分类。
代码如下:
class CustomModel (nn.Module): def __init__ (self, model_name, num_labels ): super (CustomModel, self ).__init__() self .bert_1= BertModel.from_pretrained(model_name) self .bert_2= BertModel.from_pretrained(model_name) self .cross_attention = CrossAttention(self .bert_1.config.hidden_size) self .classifier_prompt = nn.Linear(self .bert_1.config.hidden_size + 1 , num_labels) self .classifier_mixed = nn.Linear(self .bert_2.config.hidden_size + 3 , num_labels) self .loss_fn = FocalLoss(alpha,reduction=None ) def forward ( self, prompt_input_ids, prompt_attention_mask, answer_input_ids, answer_attention_mask, prompt_length_feature, answer_length_feature, answer_isna_feature, labels=None ): prompt_outputs = self .bert_1(input_ids=prompt_input_ids, attention_mask=prompt_attention_mask) prompt_hiddens = prompt_outputs.last_hidden_state answer_outputs = self .bert_2(input_ids=answer_input_ids, attention_mask=answer_attention_mask) answer_hiddens = answer_outputs.last_hidden_state cls_prompt = prompt_hiddens[:, 0 , :] cls_prompt_with_feature = torch.cat([cls_prompt, prompt_length_feature], dim=-1 ) logits_prompt = self .classifier_prompt(cls_prompt_with_feature) loss_f1 = self .loss_fn(logits_prompt, labels) if labels is not None else None attended_output = self .cross_attention(prompt_hiddens, answer_hiddens) cls_mixed = attended_output[:, 0 , :] cls_mixed_with_features = torch.cat([cls_mixed, answer_length_feature, answer_isna_feature, prompt_length_feature], dim=-1 ) logits_mixed = self .classifier_mixed(cls_mixed_with_features) loss_f2 = self .loss_fn(logits_mixed, labels) if labels is not None else None if labels is not None : total_loss = w_1 * loss_f1 + w_2 * loss_f2 return total_loss, logits_prompt, logits_mixed else : return None ,logits_prompt, logits_mixed
TinyBert
使用的TinyBert是huggingface中的huawei-noah/TinyBERT_General_4L_312D: https://huggingface.co/huawei-noah/TinyBERT_General_4L_312D。
“Huawei Noah’s TinyBERT_General_4L_312D” 是一种轻量级的预训练语言模型,它是基于 Transformer 的架构,旨在为各种自然语言处理(NLP)任务提供高效的解决方案,同时保持较低的计算资源消耗。
TinyBERT 是 Huawei Noah 提出的一个轻量级的 BERT 变种,它通过模型压缩技术(如知识蒸馏)将 BERT 模型的大小和计算复杂度大幅度减少,同时尽可能保留 BERT 的性能。TinyBERT 适用于资源受限的环境,如移动设备、嵌入式设备等。
模型结构 :
4 层(4L) :该模型有 4 层 Transformer 编码器,相较于 BERT 的 12 层,它显著减少了模型的规模,使得推理速度更快。312 维(312D) :每一层的隐藏层维度为 312,相比 BERT 的 768 维度进一步减少了模型的存储需求。
对于给定文本的tokens和掩码,TinyBert能生成包含文本上下文信息的隐藏层输出:(batch_size, seq_len, hidden_size)
self .bert_1(input_ids=prompt_input_ids, attention_mask=prompt_attention_mask)prompt_hiddens = prompt_outputs.last_hidden_state
可以通过初始字符’[cls]'对应的信息,获取上下文信息,可用于文本分类
cls_prompt = prompt_hiddens[:, 0 , :]
训练模型
使用交叉验证来选择合理模型
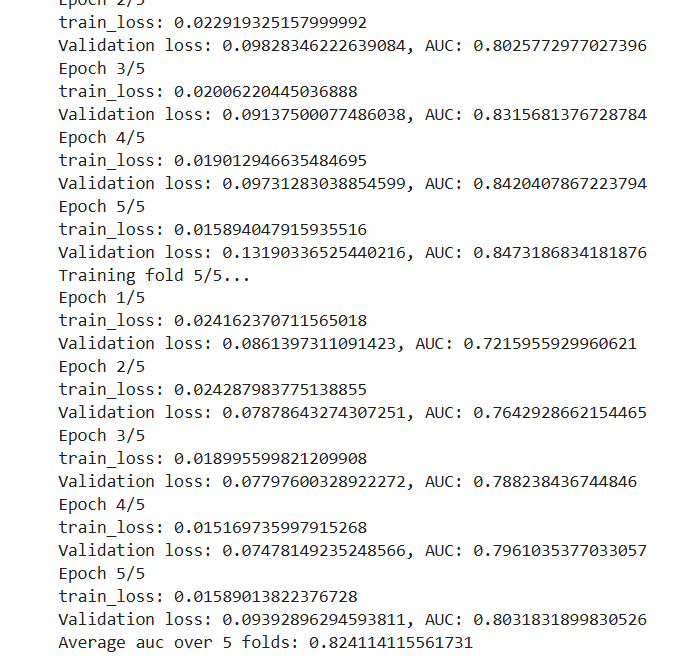
源码文件’StratifiedKFold.ipynb’中,定义了模型和一系列超参数,并采用层次化交叉验证来选择合理的超参数,代码如下:
def stratified_k_fold_cross_validation (model, dataset, labels, k=5 , num_epochs=3 , batch_size=800 , device=None ): skf = StratifiedKFold(n_splits=k, shuffle=True , random_state=42 ) all_losses = [] all_aucs = [] if torch.cuda.device_count() > 1 : print (f"Using {torch.cuda.device_count()} GPUs!" ) model = torch.nn.DataParallel(model) initial_model_params = model.state_dict() for fold, (train_idx, val_idx) in enumerate (skf.split(dataset, labels)): print (f"Training fold {fold + 1 } /{k} ..." ) model.load_state_dict(initial_model_params) train_subset = Subset(dataset, train_idx) val_subset = Subset(dataset, val_idx) train_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True ) val_loader = DataLoader(val_subset, batch_size=batch_size, shuffle=False ) optimizer = AdamW(model.parameters(), lr=5e-5 ) scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min' ) model.to(device) for epoch in range (num_epochs): print (f"Epoch {epoch + 1 } /{num_epochs} " ) train_loss = train(model, train_loader, optimizer, device) print (f"train_loss: {train_loss} " ) val_loss,auc = evaluate(model, val_loader, device) print (f"Validation loss: {val_loss} , AUC: {auc} " ) all_aucs.append(auc) avg_aucs = sum (all_aucs) / len (all_aucs) print (f"Average auc over {k} folds: {avg_aucs} " ) return avg_aucs def train (model, train_loader, optimizer, device ): model.train() total_loss = 0 for batch in train_loader: batch = {k: v.to(device) for k, v in batch.items()} total_loss, _,_ = model( prompt_input_ids=batch['prompt_input_ids' ], prompt_attention_mask=batch['prompt_attention_mask' ], answer_input_ids=batch['answer_input_ids' ], answer_attention_mask=batch['answer_attention_mask' ], prompt_length_feature=batch['prompt_length_feature' ], answer_length_feature=batch['answer_length_feature' ], answer_isna_feature=batch['answer_isna_feature' ], labels=batch['labels' ] ) total_loss=torch.mean(total_loss) optimizer.zero_grad() total_loss.backward() optimizer.step() total_loss += total_loss.item() avg_loss = total_loss / len (train_loader) return avg_loss from sklearn.metrics import roc_auc_scoredef evaluate (model, eval_loader, device ): model.eval () total_loss = 0 all_labels = [] all_preds = [] with torch.no_grad(): for batch in eval_loader: batch = {k: v.to(device) for k, v in batch.items()} total_loss,_,logits_mixed = model( prompt_input_ids=batch['prompt_input_ids' ], prompt_attention_mask=batch['prompt_attention_mask' ], answer_input_ids=batch['answer_input_ids' ], answer_attention_mask=batch['answer_attention_mask' ], prompt_length_feature=batch['prompt_length_feature' ], answer_length_feature=batch['answer_length_feature' ], answer_isna_feature=batch['answer_isna_feature' ], labels=batch['labels' ] ) logits_mixed = F.softmax(logits_mixed, dim=-1 ) total_loss = torch.mean(total_loss) total_loss += total_loss.item() all_labels.append(batch['labels' ].cpu().numpy()) all_preds.append(logits_mixed.cpu().numpy()) all_labels = np.concatenate(all_labels) all_preds = np.concatenate(all_preds) auc = roc_auc_score(all_labels, all_preds[:, 1 ]) avg_loss = total_loss / len (eval_loader) return avg_loss, auc
在选定的一组合理的超参数下,模型在验证集上的auc值为0.8241:
重新训练模型
选好超参数后,模型需要在完整训练集上重新训练,这部分代码,位于源文件idea_model.ipynb中,其中源文件中trained_model.pth为训练完的权重。
def train (model, train_loader, device ): if torch.cuda.device_count() > 1 : print (f"Using {torch.cuda.device_count()} GPUs!" ) model = torch.nn.DataParallel(model) optimizer = AdamW(model.parameters(), lr=5e-5 ) scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min' ) model.to(device) model.train() for epoch in range (num_epochs): print (f"Epoch {epoch + 1 } /{num_epochs} " ) total_loss = 0 for batch in train_loader: batch = {k: v.to(device) for k, v in batch.items()} total_loss, _,_ = model( prompt_input_ids=batch['prompt_input_ids' ], prompt_attention_mask=batch['prompt_attention_mask' ], answer_input_ids=batch['answer_input_ids' ], answer_attention_mask=batch['answer_attention_mask' ], prompt_length_feature=batch['prompt_length_feature' ], answer_length_feature=batch['answer_length_feature' ], answer_isna_feature=batch['answer_isna_feature' ], labels=batch['labels' ] ) total_loss=torch.mean(total_loss) optimizer.zero_grad() total_loss.backward() optimizer.step() total_loss += total_loss.item() train_loss=total_loss / len (train_loader) print (f"train_loss: {train_loss} " ) model_save_path = 'trained_model.pth' torch.save(model.state_dict(), model_save_path) print (f"Model saved to {model_save_path} " )
实验结果分析
在源文件idea_model.ipynb中,最后使用测试集放到模型,输出的 logits_mixed,再加上一次softmax,形成不同标签的概率,然后依照此生成submission.csv文件。
然后将这个文件上传到kaggle,得到分数,如下图:
这个分数和在交叉验证中得到的结果差不多。
参考文献
无