model architecture
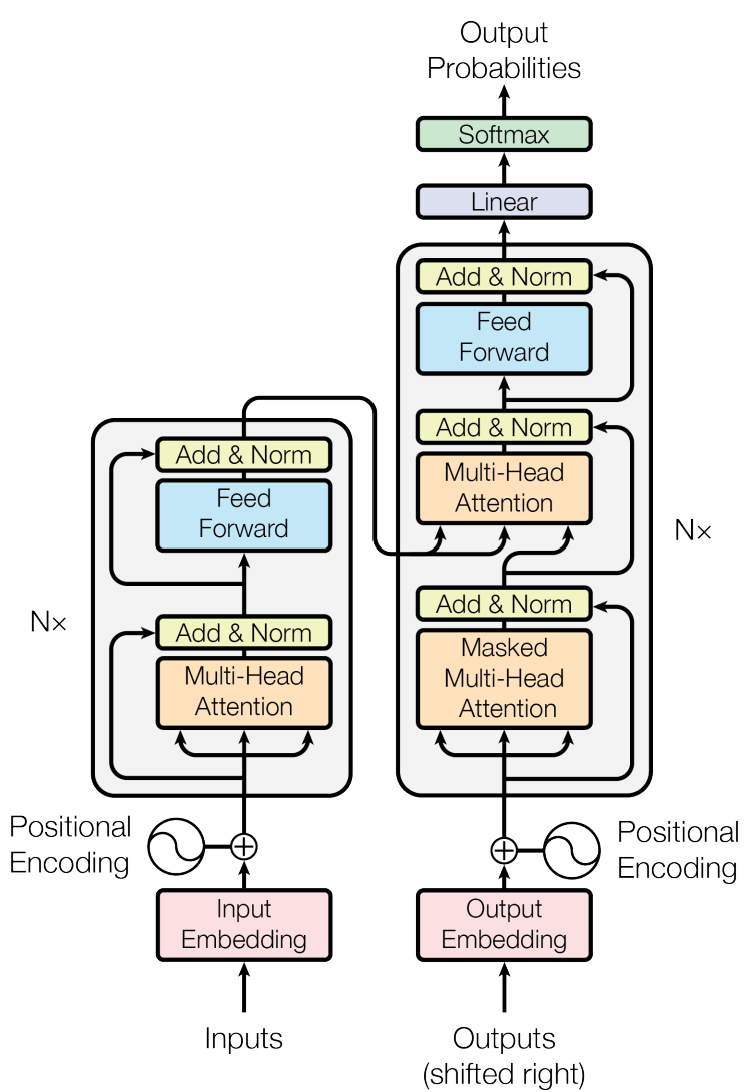
Inputs: A paragraph of English consists of (i.e. batch_size) sentences. Each sentence has (i.e. seq_length) words at most.
Outputs: A paragraph of Chinese translated from Inputs.
Encoder outcome: the feature matrix containing position , context, semantic information
Decoder: auto-regressive , consuming the previously generated symbols as additional input when generating the next.
For example:
Inputs : I love u. ()
- Learning feature from Inputs (Encoder)
- send the feature to Decoder
- generate the Chinese ’ 我爱你’ word by word
Training period : Given the Inputs(Encoder) and Outputs,Label(Outputs),the loss function is the cross-entropy between the probability vector and ground true.
Attention Mechanism
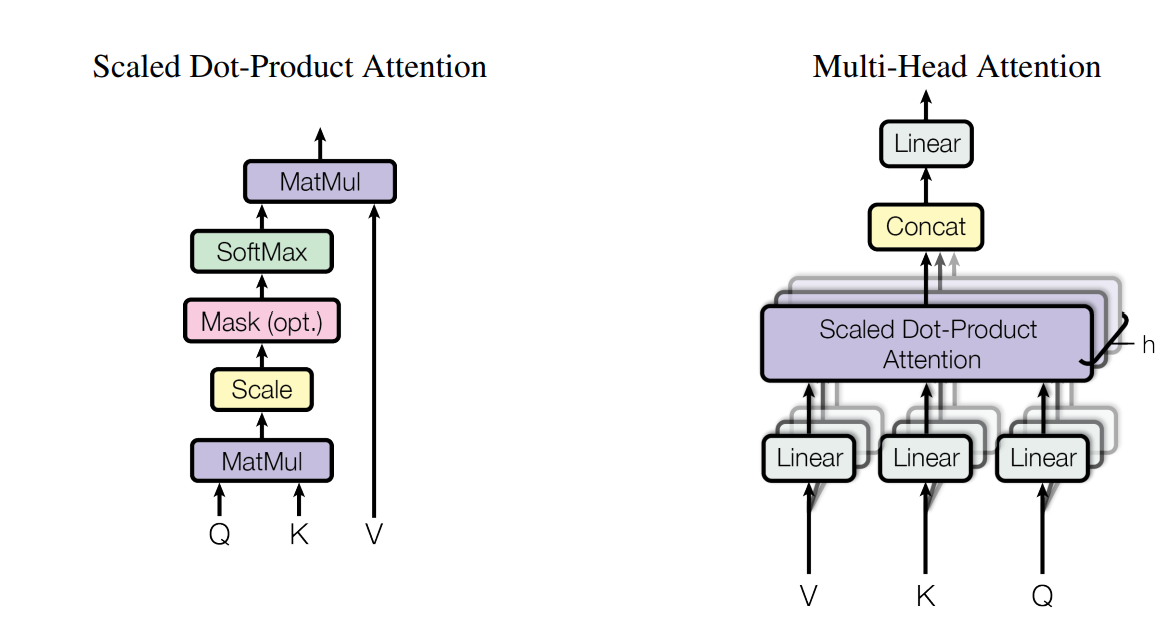
attention between query and key:
modified value:
- Add&Norm: residual connections and Layer Norm
- FFN: Linear layer , ReluActivation , Linear
Embedding
Positional Embedding:
Transformer cant extract the position information without the Positional Encoding