Motivation
Scaling up is all you need.
scale: size of datasets, the number of model parameters, the range of effective receptive field, and the computing power .
scale principle: efficiency ( simplicity scalability ) VS accuracy
Unlike the advancements made in 2d or NLP field,the previous works in 3D vision had to focus on improve the accuracy of the model due to the limited size and diversity of point cloud data available in separate domains .
The time consumption of point transformer V1 or V2:
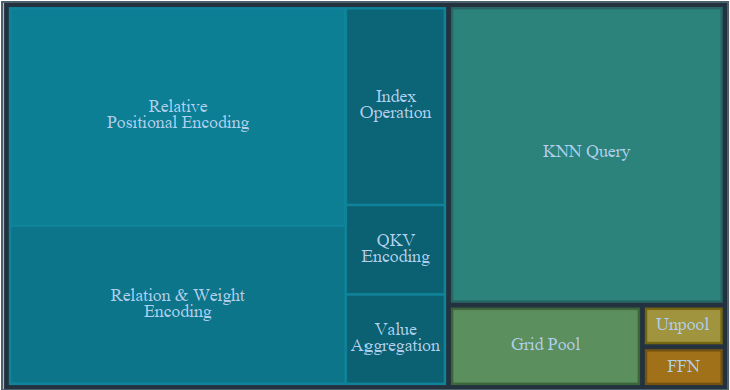
KNN Query and RPE occupy a total of 54% of forward time ,which pays too much attention to design the overfitting pattern to improve the accuracy of the 3d task.
This paper consider the concept about the trade off between the efficiency and accuracy , leveraging the potential of the power of scalability on the ‘‘weak’’ dataset to improve the accuracy .
- remove the limitation of permutation invariance of points clouds
- modify the time-consuming Positional encoding
- explore the potential of the dataset (Data Augmentation)
The idea : **Any initial accuracy gaps can be effectively bridged by harnessing the scalability potential ** dominate the whole paper.
overall architecture

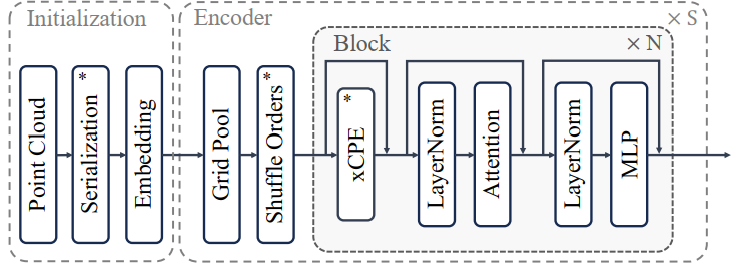
Point Cloud Serialization
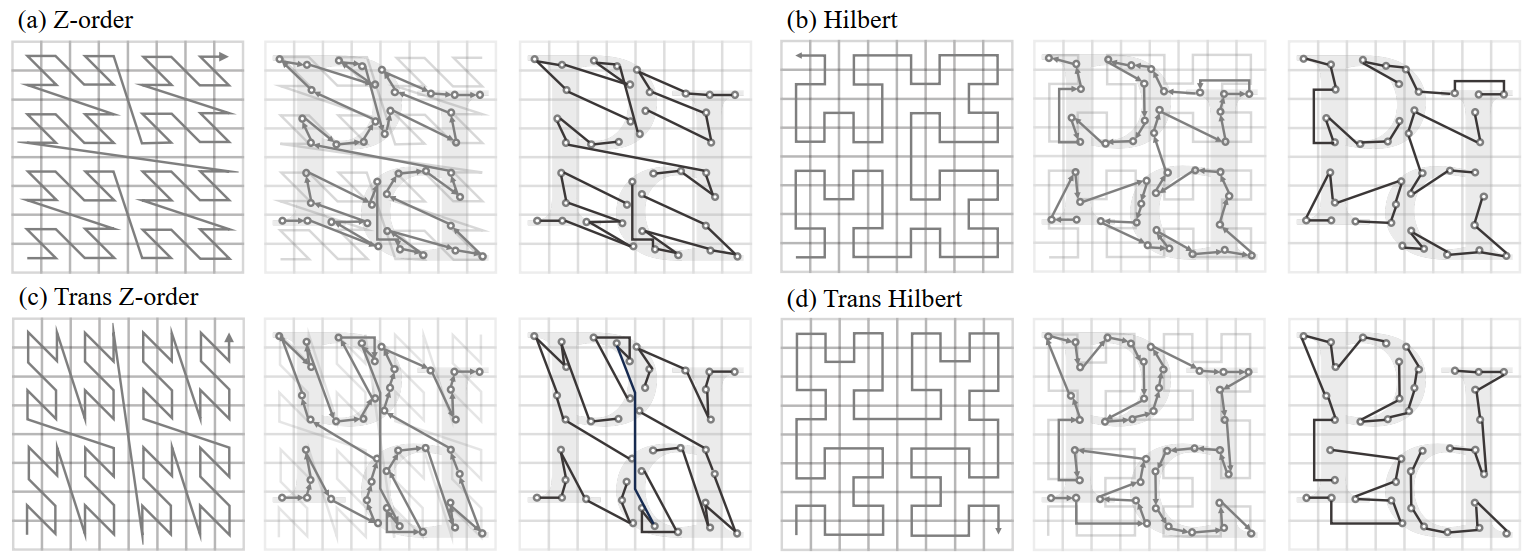
Space-filling curves
Bijective function , where is the dimensionality of the space, which is 3 within the context of point clouds and also can extend to a higher dimension .
Serialized encoding
the serialization of point clouds is accomplished by sorting the codes resulting from the serialized encoding
Serialized Attention
Image transformers , benefiting from the structured and regular grid of pixel data, naturally prefer window and dot-product attention mechanisms. However, this advantage vanishes when confronting the unstructured nature of point clouds.
With the serialized points cloud , now we can choose to revisit and adopt the efficient window and dot-product attention mechanisms as our foundational approach.
Evolving from window attention, this paper define patch attention, a mechanism that groups points into non-overlapping patches and performs attention within each individual patch.
Patch grouping
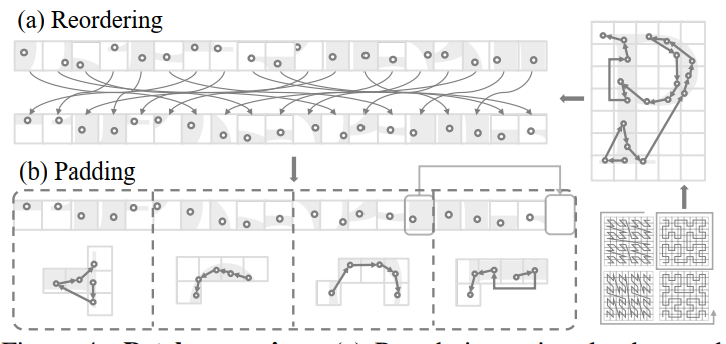
Patch interaction
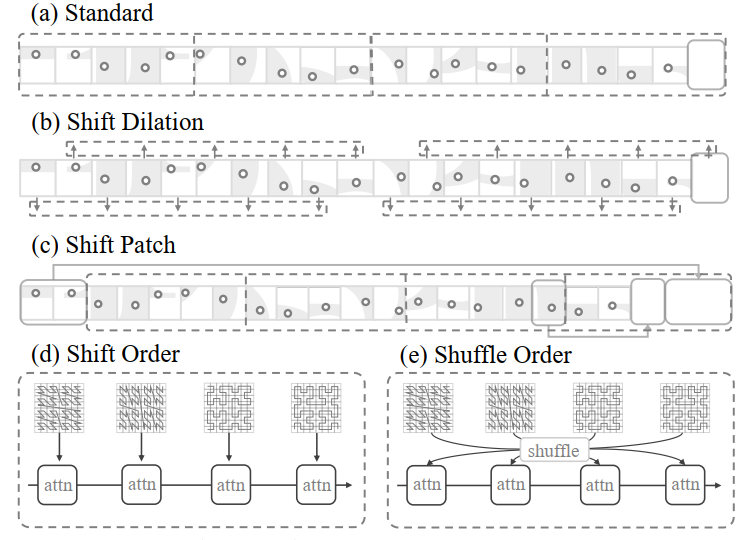
The serialized order of the point cloud data is dynamically varied between attention blocks
prevent the model from overfitting to a single pattern and promotes a more robust integration of features across the data
simpler position encoding
conditional positional encoding
This paper presents an enhanced conditional positional encoding (xCPE), implemented by directly prepending a sparse convolution layer with a skip connection before the attention layer.