生成模型对比
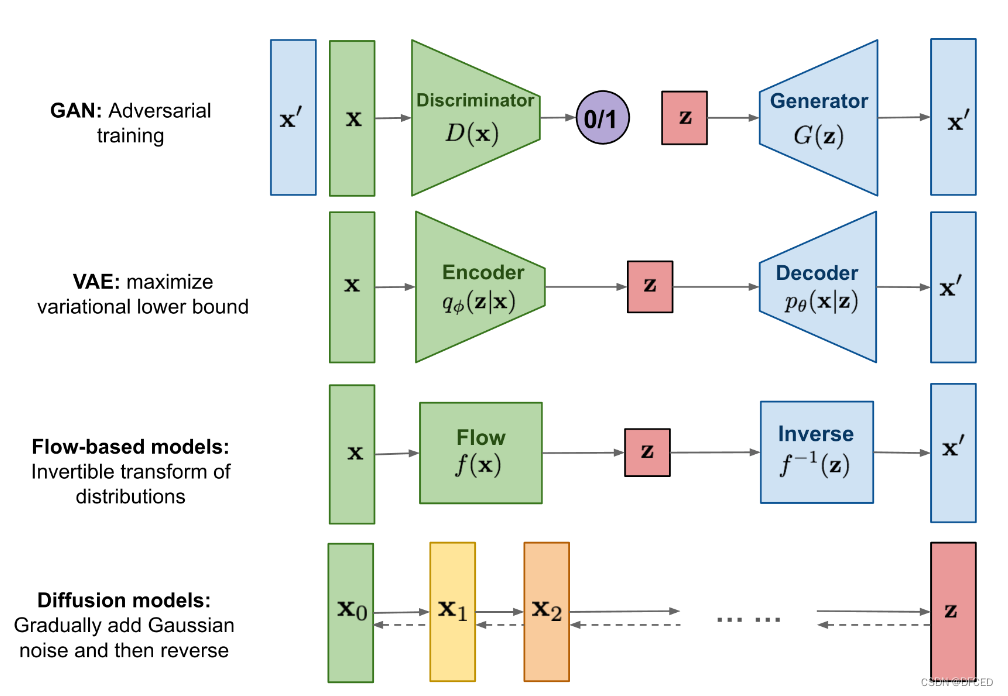
GAN网络由discriminator和generator组成,discriminator致力于区分x和x‘,而generator致力于生成尽可能通过discriminator的样本,迭代多次,最终generator生成的样本越来越像x,即我们需要的生成式样本。
VAE是学习分布函数的网络,但是这里的分布函数是从样本空间到语义空间的。
Flow-based models是真正开始学习分布的网络结构
overall
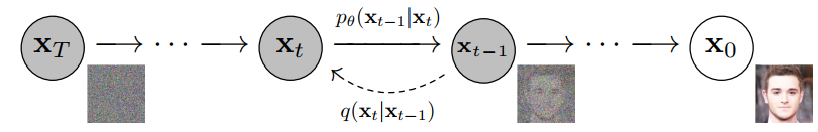
forward process (diffusion process 扩散过程):从右到左 X0→XT
reverse process (denoising process 去噪过程):从左到右 XT→X0
扩散过程和去噪过程,都视为Markov 过程。
x0∼q(x0)
任务为:学习一个分布(distribution ) pθ(x0:T),并使用pθ(x0):=∫pθ(x0:T)dx1:T来估计q(x0)。
具体来说,在训练过程中,这是一个扩散过程,markov转移方程q(xt∣xt−1)为高斯分布,并且它的参数是不需要学习的,也就是说q(x0:T)是已知的;在生成过程中,markov的转移方程q(xt−1∣xt)也是高斯分布,但是q(xt−1∣xt)是无法计算的,只能通过学习即pθ(xt−1∣xt)来近似估计。
这里注意两点
- pθ(xt−1∣xt) 应该为高斯分布,但是它的参数是学习出来的
- 在扩散过程中学习出这些参数
loss function: (不方便使用交叉熵 i.e. 最大似然估计)
Eq[−logpθ(x0)]≤Eq[−logq(x1:T∣x0)pθ(x0:T)]=Eq[−logp(xT)−t≥1∑logq(xt∣xt−1)pθ(xt−1∣xt)]=:L
扩散过程
扩散过程是一个转移函数为高斯函数的markov 过程:
q(x1:T∣x0):=t=1∏Tq(xt∣xt−1),q(xt∣xt−1):=N(xt;1−βtxt−1,βtI)
这里βt在文章中设置为超参数,βt∈(0,1),并且随着t单调递增,文章中取βt为0.001到0.02。
在任何时刻t,使用求边缘概率分布或者参数重组方式,可以得到:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)αt:=1−βt and αˉt:=s=1∏tαs
也可以认为:xt为x0的仿射变换
xt=αˉtx0+(1−αˉt)ϵϵ∼Nd(0,1)
此时将loss 函数继续改写:
L:=Eq[LTDKL(q(xT∣x0)∥p(xT))+t>1∑Lt−1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0−logpθ(x0∣x1)]
我们使用贝叶斯公式来求 q(xt−1∣xt,x0):
q(xt−1∣xt,x0)q(xt−1∣xt,x0)whereμ~t(xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∝exp(−21(βt(xt−αtxt−1)2+1−at−1(xt−1−αt−1x0)2−1−at(xt−αtx0)2))=N(xt−1;μ~t(xt,x0),βtI),:=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xtandβ~t:=1−αˉt1−αˉt−1βt
继续做变换(参数重组):
x0=αˉt1(xt−(1−αˉt)ϵ)ϵ∼Nd(0,1)
得到
μ~t(xt,x0)=αt1(xt−1−αˉtβtϵ)β~t:=1−αˉt1−αˉt−1βt
降噪过程
我们需要根据扩散过程和loss函数来确定pθ:
- 在训练时 LT是一个常数,因为q的各参数已知,而xt在降噪过程中也是给出的
- L0也可以不用考虑,因为β1很小,也就是说,在扩散过程中,x1相对于x0加的噪声很小,文章中实际上没必要生成x0,后续文章中写到最终生成的其实是μθ(x1,1)。
- Lt−1才是真正需要考虑的
根据loss函数中Lt−1来看,我们需要使用 pθ(xt−1∣xt) 来逼近 q(xt−1∣xt,x0) ,那么显然 pθ(xt−1∣xt) 也必须为高斯分布:
pθ(xt−1∣xt)=N(xt−1;μ~θ(xt,t),σt2I)
这里需要注意的是,q(xt−1∣xt,x0)化简后实际上只和βt,xt,ϵ有关,βt已知,xt是给出的,所以最关键的就是如何估计ϵ。
ϵ其实是从x0到xt所加的噪声(标准化过),在降噪过程中,我们应该将ϵ视为一种待估计的量,实际上就是数理统计中参数估计。传统数理统计中有很多办法,文章中使用神经网络做估计,在数理统计的观点下,机器学习的目标就是学习一个好的样本统计量 。
形式化后就是:
μ~θ(xt,t)=αt1(xt−1−αˉtβtϵθ(xt,t))σt2=β~t=1−αˉt1−αˉt−1βt
参数重组后,得到xt−1和xt的关系为:
xt−1=μ~θ(xt,t)+σtz;z∼Nd(0,1)xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))+σtz
算法
重新改写一下loss 函数最终变为
L(θ)=Ex0,ϵ[2σt2αt(1−αˉt)βt2ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)2]Lsimple(θ):=Et,x0,ϵ[ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)2]

这里的ϵθ()模型可以选很多种,文章中采用的是UNET。