Motivation
Point Cloud:
- disordered (permutation-invariant )
- unstructured
which make it difficult to designing a neural networks to process.
All operations of Transformer are parallelizable and order-independent , which is suitable for PT feature learning.
In NLP ,the classical Transformer use the positional encoding to deal with the order-independence .
the input of word is in order, and word has basic semantic, whereas point clouds are unordered, and individual points have no semantic meaning in general.
Therefore,we need to modify the classical Transformer structure!
overall
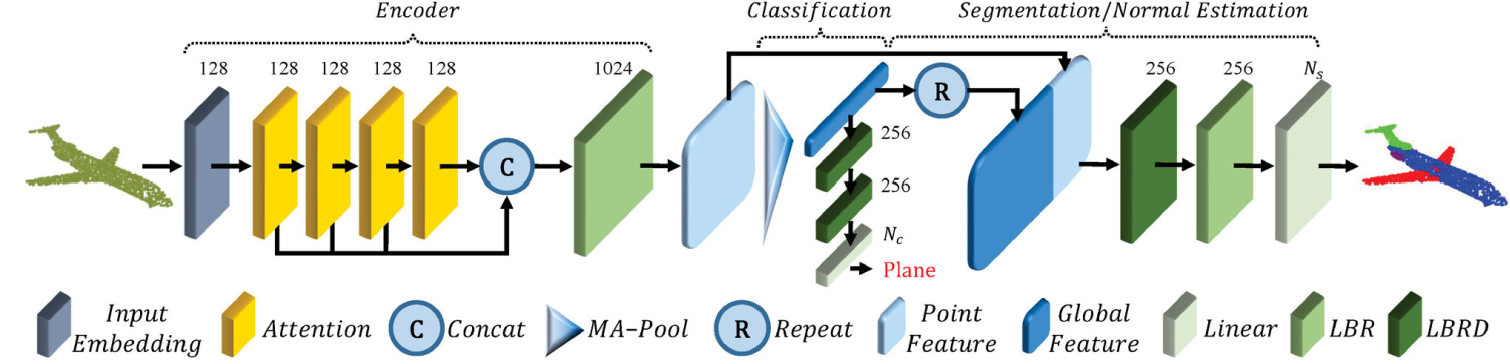
Offset-Attention and Naive Self-Attention
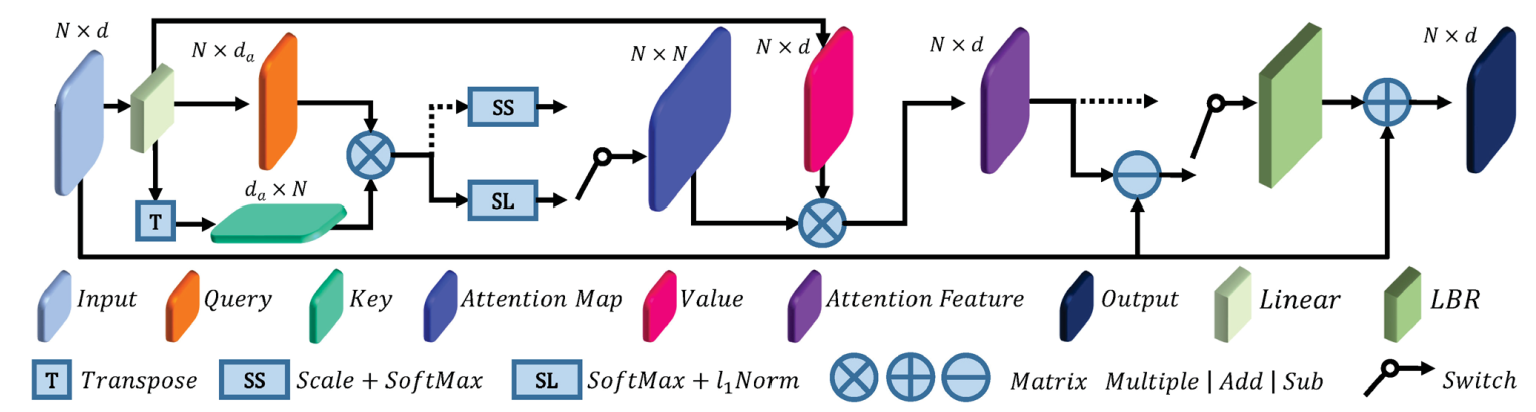
The dotted line represents the Self-Attention
Offset-Attention
Inspired by the Laplacian Matrix in GCN, the paper proposes the Offset-Attention structure.
- original:
- modified:
Here, is analogous to a discrete Laplacian operator.
is an identity matrix comparable to the diagonal degree matrix of the Laplacian matrix and is the attention matrix comparable to the adjacency matrix
- Inspired : Graph convolution networks show the benefits of using a Laplacian matrix to replace the adjacency matrix . That is, Laplacian operator is more capable of extracting global feature
softmax and l1_norm
-
original: scaled and softmax
-
modified: softmax followed by l1_norm
-
Our offset-attention sharpens the attention weights and reduces the influence of noise, which is beneficial for downstream tasks.
Neighbor embedding
PCT with point embedding is an effective network for extracting global features.
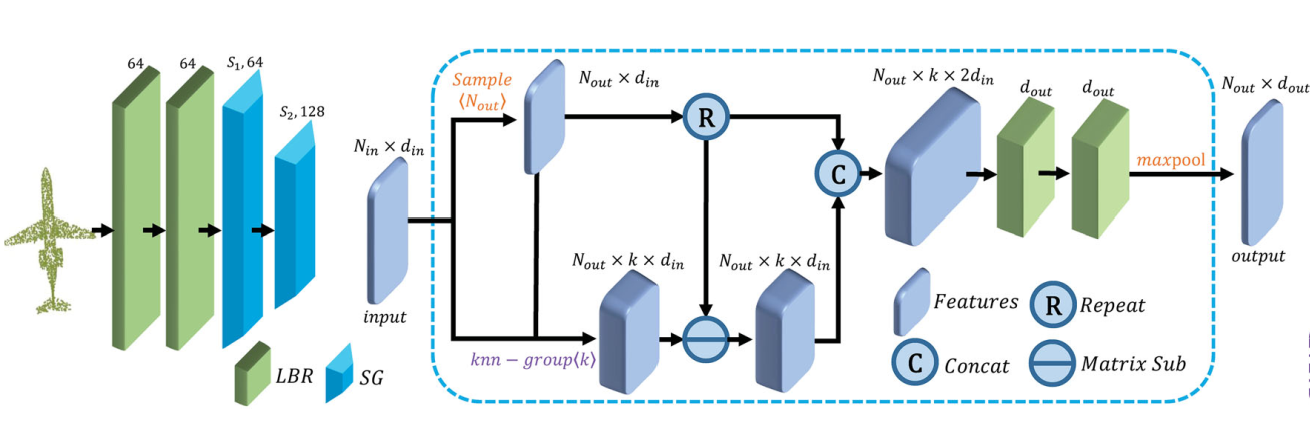
- use farthest point sampling (FPS) algorithm to down sample to (find the cluster center)
- use k nearest neighbor (knn) algorithm to find their neighborhood
- The neighbor information is aggerated.